Linux kernel: Energy Aware scheduling (EAS)
Energy Aware scheduling
之前寫的作業報告,我覺得可以分享出來
hackmd版:https://hackmd.io/@Daichou/ByzK-S60E
主要文章:https://www.linaro.org/blog/energy-aware-scheduling-eas-progress-update/
背景
本文主要以linaro 於2015年提出之EAS(Energy aware scheduling)框架看當今Linux kernel 5.0以後從EAS與Android端整合回kernel的EAS與EM(energy model)。
自從Arm big.LITTLE 從原本的硬體切換叢集大小核,到後來的HMP(heterogeneous multi-processing),傳統Linux的SMP排程方式不敷使用,由於傳統Linux kernel的CFS(Completely Fair Scheduler)是以吞吐量(throughput)為主,對於移動平台的功耗掌控不甚理想。因此Arm與Linaro團隊提出了EAS作為對於HMP下Linux CFS,cpuidle,cpufreq子系統的加強。後來導入EM 框架,作為EAS與driver與其他Linux子系統,如:device tree與Thermal(目前仍未連接)的介面。
Energy Model Framework
Interface
EM(energy model Framework)是Linux kernel特別抽出的介面,用來讓子系統或是driver可以透過em_register_perf_domain()函式註冊一個特別情況下的時脈與功耗的關係(performance domain)。

如上圖可見driver透過em_register_perf_domain註冊效能資料,Kernel透過em_pd_energy()取得功耗估計,而em_cpu_get()用以取得EM中的energy model table的資料。目前僅有Scheduler需要這些資料,不過Linux kernel預期會有更多子系統需要這些資料,因此將特別抽出建立一層抽象化。
OPP(operating performance points)
由於當前SOC盛行,SOC有許多子模塊(例如:CPU cluster),這些子模塊可以依照使用情境給予不同的頻率與電壓組合,並不一定需要整個SOC依照相同頻率運作,這些子模塊通常被分為domain,各domain可以有多組頻率與電壓組合被稱為operating performance points(OPP)。OPP透過device tree source(dts)由開發者建立,通常於開機時初始化。

(資料來源:https://www.linaro.org/assets/blog/EAS-image-11-f4a331f605b5adbd4d8330917f421070c2b0fc0e7d4fd2e22de1cbe2bf8e83c5.jpg)
以上圖為例由於CPU的算力與功率是曲線而非直線,因此透過OPP可以增加EM推算未來功耗的準確度,這項設計可讓EM預測功耗的線性內插運算更為精準。
Performance domain(perf_domain)

整個performance domain結構如上圖。每個cpu run queue會指向一個root_domain(用以表達一個cpu set),每個root_domain會用linked list儲存多個perf_domain,每個performace domain中的CPU必須是相同的microarchitecture(例如均為Cortex-A53)且當調整一個perf_domain的物理參數(如電壓等),整個perf_domain中的硬體均會一起被調整,每個perf_domain對應的em_perf_domain會透過em_register_perf_domain()與對應的callback function建立em_cap_state。以從device tree建立的方式為例,em_register_perf_domain()會透過OPP的_get_cpu_power()依照:
Power = Capacity * Voltage^2 * frequency
公式將OPP轉成mW、frequency以及cost組合存入em_cap_state,其中cost計算方式為:
Cost = max_cpu_frequency * em_cap_state.power/em_cap_state.frequency
perf_domain與root_domain對應到實際上的SOC的關係則是如下圖。通常一個root_domain對應到一個SOC,而perf_domain對應到其中的CPU cluster。如果cluster中的CPU可以特別調頻,則可以在拆分更多perf_domain。

Energy Aware Scheduler
EAS 基本上並非完全提出一個新的scheduler,而是在更改現有scheduler(CFS)在挑選指派cpu的方式。藉此調整HMP的功耗。
CPU capacity
CPU capacity是用以表達當CPU以最高頻率運行時的throughput。透過CPU capacity與scheduler 從Per-Entity Load Tracking(PELT)取得task運作數據了解該CPU的忙碌程度。CPU capacity是開機時在建立CPU topology時解析device tree建立。系統可以透過arch_scale_cpu_capacity()讀取該值。
policy
Energy aware scheduling透過選取CPU的方式,主要透過select_task_rq_fair這個函式將任務發配給cpu runqueue。而整個scheduler有兩個情境會需要執行此函式:
- execve -> sched_exec
- wake up一個task
task的能耗預測
透過Energy Model提供的em_pd_energy()預測,推算方式如下: \( cs : domain\ capacity\ state \)
透過頻率與CPU utilization的關係我們可以找到大於當前CPU uilization最小的cs。
\( cs\ capacity = {CPU\ max\ capacity} * \dfrac{cs\ frequency}{CPU\ max\ frequency}\\\\ \) \( \\Predict\ CPU\ energy = cpu\ utilization *\dfrac{cs\ power}{cs\ capacity} ...(1)\\ \) \( = \dfrac{cs\ power * CPU\ max\ freq}{cs\ frequency} * \dfrac {CPU\ utilization}{CPU\ max\ capacity} ...(2) \)
由於
\(
\dfrac{cs\ power * CPU\ max\ freq}{cs\ frequency} = cs\ cost(em\_cap\_state.cost)
\)
所以
\(
Predict\ CPU\ energy =\dfrac{CPU\ utilization * cs\ cost}{CPU\ max\ capacity}
\)
Linux kernel中使用化約過的(2)式做運算,而我們以下範例使用直觀的(1)式。範例:
當前狀況CPU01為同perf_domain,CPU23為同perf_domain,若P1(平均util=200):
CPU0: 400 / 512 * 300 = 234
CPU1: 100 / 512 * 300 = 58
CPU2: 600 / 768 * 800 = 625
CPU3: 500 / 768 * 800 = 520
共1437 若P1移到CPU1
CPU0: 200 / 341 * 150 = 88
CPU1: 300 / 341 * 150 = 131
CPU2: 600 / 768 * 800 = 625
CPU3: 500 / 768 * 800 = 520
共1364 若P1移到CPU3(無法移到2除非調整OPP)
CPU0: 200 / 341 * 150 = 88
CPU1: 100 / 341 * 150 = 43
CPU2: 600 / 768 * 800 = 625
CPU3: 700 / 768 * 800 = 729
共1485 透過此方式可知將task放到CPU1有最佳功耗。
EAS 時間複雜度
由上的運算可知每次運算(select_task_rq_fair)需要遍歷root_domain下所有的perf_domain,並且需要計算每個CPU與其OPP是落在哪個效能區間,依照kernel文件給出的時間複雜度如下:
\[Complexity = Nd * (Nc + Ns)\\ Nd: Number\ of\ performance\ domain\\ Nc: Number\ of\ CPUS\\ Ns: total\ number\ of\ OPPS\\ (ex:\ if\ 2\ perf\ domain\ with\ 4\ OPPs\ each,\ Ns\ =\ 8)\]
此對於task wake up的情況來說,此情況對於時間複雜度很敏感,如果EAS(EM)複雜度過高會導致OS反應不佳,因此EM設立了EM_MAX_COMPLEXITY門檻(預設2048),若Complexity數值高過此數值則不啟用EAS,一般開發人員也可以透過:
- 分隔root_domain減少domain中的CPU數量降低複雜度
- 減少EAS task wake up的複雜度(需要自己上patch),不過難度很高
來減少task wake-up的延遲。
EAS成立假設
EAS要能夠成功在不影響效能運作,且達成能耗最佳化必須建立在以下三個假設:
- 所有CPU都有足夠的idle時間:確保task可以不受效能限制的運行,使PELT計量的task utilization為正確的。
- 每個task都被供給足夠的CPU capacity:原因同上。
- 每個CPU都有足夠的剩餘capacity,以滿足task wake-up且task的blocking/sleeping愈規律愈好
這些假設必須在CPU低於80% capacity情況下才可以成立,當高於此值稱為over-utilization,此狀況下EAS的會無法得到足夠的選擇,導致效能損失。
Over-utilization
為了確保EAS不要在效能吃緊時影響效能,EAS建立了一個狀態 “over-utilization” 。當CPU使用了超過 80% 的capacity時,SG_OVERUTILIZED這個flag會被設立,這時scheduler會放棄使用EAS的指派CPU機制,而改用原先CFS的指派方式:選擇同一schedule domain下負載最小的CPU(最idle的CPU)或是相鄰schedule domain下覆載最小的CPU。
此機制的檢查是在:
1.透過SCHED_SOFRIRQ發生時,透過update_sg_lb_stats()檢查並更新sched_group的統計數據
2.新的task被放入CFS的紅黑樹時檢查。
load balance
Linux kernel 透過SCHED_SOFTIRQ這個softirq對應的action函式驅動scheduler檢查是否需要進行load balance,然而在EAS啟動時(sched_energy_enabled()回傳值為真)情況下,會直接將當前情況視為沒有負載不均衡(find_busiedt_group()會清除imbalance flag並回傳NULL)。因為EAS很容易造成大小核任務分配不均的情況。然而只要root domain中其中個CPU發生over-utilization的情況,即便EAS啟動,load balance仍會進行。
Dependency
EAS需要以下滿足以下相依性:
- 非對稱CPU架構(即SD_ASYM_CPUCAPACITY flag必須開啟),Ex: big.LITTLE架構。
- Energy model:用來提供效能參數。
- EM複雜度低於門檻。
- Schedutil governor:為Linux 4.7以後新增的governor,用以動態根據utilization調節CPU freqency,EAS只能使用這個governor。
- Scale-invariant utilization signals:PELT必須能夠給出frequency-invariant and CPU-invariant PELT訊號以給出正確的功耗預測。
綜合5.與6.由於必須要提供frequency-invariant訊號,因此系統的util必須是frequency-invariant。因此在Schedutil governor中使用:
\[next\_freq\ =\ 1.25\ *\ max\_freq\ *\ \frac{ utilization} {max\_cpu\_capacity}\]
作為調整公式(若為variant,max_freq項需替換成cur_freq)。當CFS的run queue中的utilization改變時會觸發cpufreq_update_util(),由於在EAS情況下會使用SchedUtil governor,會對應到sugov_update_single()或是sugov_update_shared()進行頻率更新。
在linaro文章中提到的是cpufreq governor,其已經被SchedUtil governor正式取代。
效能數據
可以發現負載愈小節能效果愈好,因為task可以指派的選項比較多,可以找到更好的結果。但是EAS仍會造成一些效能損失。
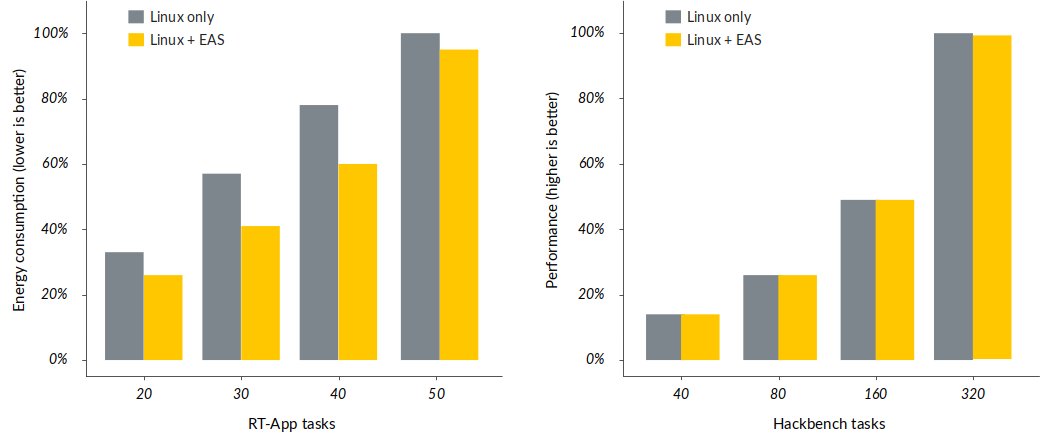
資料來源:ARM
未來發展
1.EM是否該包含GPU等其他運算單元。
目前移動裝置中仍未出現異質的GPU設計,所以仍未限包含GPU的需求
2.是否有其他子系統需要EM的參數。